Methods: PipeOps in mlr3
Introduction
I’ll use the Boardgame Rating data from episode 1 of Sliced to illustrate the use of mlr3 for pre-processing. The challenge for that episode is to predict the scores given to boardgames by the boardgamegeek website (https://boardgamegeek.com/) using predictors that describe the game.
This post is a continuation of Methods: Introduction to mlr3. If you are new to mlr3 you ought to start with that earlier post.
Reading the data
library(tidyverse)
library(mlr3verse)
# --- set home directory -------------------------------
home <- "C:/Projects/kaggle/sliced/s01-e01"
# --- read downloaded data -----------------------------
trainRawDF <- readRDS( file.path(home, "data/rData/train.rds") )
testRawDF <- readRDS( file.path(home, "data/rData/test.rds") )
print(trainRawDF)## # A tibble: 3,499 x 26
## game_id names min_players max_players avg_time min_time max_time year
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 17526 Heca~ 2 4 30 30 30 2005
## 2 156 Wild~ 2 6 60 60 60 1985
## 3 2397 Back~ 2 2 30 30 30 -3000
## 4 8147 Maka~ 2 6 60 45 60 2003
## 5 92190 Supe~ 2 6 120 120 120 2011
## 6 1668 Mode~ 2 6 90 90 90 1989
## 7 28089 Chât~ 2 4 30 30 30 2007
## 8 4854 7th ~ 2 2 120 120 120 1987
## 9 75333 Targ~ 1 4 90 90 90 2010
## 10 21791 Maso~ 2 4 45 45 45 2006
## # ... with 3,489 more rows, and 18 more variables: geek_rating <dbl>,
## # num_votes <dbl>, age <dbl>, mechanic <chr>, owned <dbl>, category1 <chr>,
## # category2 <chr>, category3 <chr>, category4 <chr>, category5 <chr>,
## # category6 <chr>, category7 <chr>, category8 <chr>, category9 <chr>,
## # category10 <chr>, category11 <chr>, category12 <chr>, designer <chr>I will not repeat the exploratory analysis, details of this can be found in my earlier post entitled Spliced Episode 1: Boardgame Rating. Instead I will concentrate on cleaning the data, extracting keywords from the text fields and filtering the important variables for use in the predictive model.
PipeOps
mlr3 is an eco-system with a large range of packages including one called mlr3pipelines, which provides a host of different PipeOps that are combined to create analysis pipelines. Such a pipeline can include both pre-processing and model fitting, so that the whole pipeline can be used for resampling or hyperparameter tuning.
Although I will concentrate on the mechanics of creating a pipeline, the first question that we should ask is why bother. After all, I analysed these data perfectly well in my early post without any pipelines. I simply did the pre-processing using dplyr and a couple of my own functions.
There are pros and cons to using pipelines that need to be considered before we jump headlong into using them.
The pros are
- Pipelines provide neat, concise code
- PipeOps remember their own state
- Pipelines avoid data leakage when resampling
- Tuning can be performed simultaneously on model hyperparameters and hyperparameters of the pre-processing
The cons are
- Coding a pipeline is yet another skill to learn
- Running a complete pipeline discourages the analyst from inspecting intermediate steps
Let we expand slightly on the pros. Some pre-processing steps involve calculations based on the actual values, for instance median imputation requires the calculation of the median of the non-missing observations. A PipeOp will remember any such calculated values and they will be available for inspection or subsequent use.
Some pre-processing steps, such as filtering the most important predictors, depends on the training data. The top 10 features based on the entire training set will not necessarily be the same as the top ten based on a sample of 80% of the training set. If we identify the top 10 from the entire training set and subsequently run a cross-validation or divide the training set into an estimation set and a validation set, then the validation data will have contributed towards the filtering. As a result the model performance in the validation will be artificially improved. Data will have leaked from the validation set into the model estimation.
Hyperparameter tuning is improved by a pipeline when we want to tune both the pre-processing and the model. For instance, we might want to ask whether to filter the top ten features or the top 15 or whatever. The number of features might interact with some aspect of the model, in which case it would be more efficient to tune both together. This is easier to organise if the entire analysis is controlled by a single pipeline.
The counter argument is that in practice the impact of data leakage is likely to be negligibly small and the gain in tuning efficiency will probably also be small. The pros are more theoretical than practical.
Separate PipeOps
I will create a series of separate PipeOps that perform distinct pre-processing steps. Only once I have all of the separate steps, will I combine them into a pipeline. Perhaps this is not how one would work in practice, but I think that it simplifies the explanation.
Sugar Functions
There are a number of sugar (helper) functions that are intended to make mlr3 easier to use. In my opinion these functions have been poorly named; the authors have gone for brevity over clarity. So I have decided to rename them. Here are my preferred names. It is unlikely that you will like my choices, so use your own or stick with the originals.
# --- po() creates a pipe operator -----------------------------
pipeOp <- function(...) po(...)
# --- lrn() creates an instance of learner ---------------------
setModel <- function(...) lrn(...)
# --- rsmp() creates a resampler -------------------------------
setSampler <- function(...) rsmp(...)
# --- msr() creates a measure ----------------------------------
setMeasure <- function(...) msr(...)
# --- flt() creates a filter ----------------------------------
setFilter <- function(...) flt(...)If I am to test the PipeOps then I will need to place the data into a Task. See my post Methods: Introduction to mlr3 for an explanation of Tasks in mlr3.
# --- define the task ------------------------------------
myTask <- TaskRegr$new(
id = "Boardgame rating",
backend = trainRawDF,
target = "geek_rating")Extreme values
The first pre-processing step will be to use median imputation to replace the small number of missing values. In these data, missing values are usually recorded as zero. So the pre-processing actually involves two steps, (a) replace 0 by missing (b) replace missing by the median of the non-missing.
I will create the the PipeOps for imputing age in gentle stages and then duplicate the process for other variables. Age records the minimum recommended age for people playing the game.
# --- dplyr: to inspect the problem ---------------------------
myTask$data() %>%
{ summary(.$age)}## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.00 8.00 11.00 10.43 12.00 42.00The value 42 is also a bit suspect, but I will return to that later.
# --- dplyr: to inspect the desired result --------------------
myTask$data() %>%
filter( age > 0 ) %>%
{ summary(.$age)}## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 3.00 10.00 12.00 10.89 12.00 42.00Mutation
There is a PipeOp called mutate that can be used to edit the data (https://mlr3pipelines.mlr-org.com/reference/mlr_pipeops_mutate.html). The required mutations must refer to named columns, in this example they are saved in a list called zeroAge. The PipeOp ageMutateOp is created as an instance of PipeOpMutate, it is given an identifier and a set of parameters.
library(mlr3pipelines)
# --- list of required mutations --------------------------------------
zeroAge <- list( age = ~ ifelse(age == 0, NA, age))
# --- define with new -------------------------------------------------
ageMutateOp <- PipeOpMutate$new(
id = "age_to_missing",
param_vals = list( mutation = zeroAge) )
# --- or use the sugar function ---------------------------------------
ageMutateOp <- pipeOp("mutate",
id = "age_to_missing",
mutation = zeroAge)
# --- if you do not like my names -------------------------------------
ageMutateOp <- po("mutate",
id = "age_to_missing",
mutation = zeroAge)
# --- apply to myTask -------------------------------------------------
ageMutateOp$train( list(myTask))[[1]]$data() %>%
{ summary(.$age)}## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 3.00 10.00 12.00 10.89 12.00 42.00 146A word of explanation about the training of ageMutateOp using myTask. PipeOps can be applied to any number of Tasks, so the Tasks are placed in a list, in this case there is only one Task so the list is a bit redundant. Training returns a list of transformed Tasks and I want the first Task in the returned list, hence [[1]]. From that Task, I take the data and after that it is the same code as I used before.
Median Imputation
The second step is median imputation for which there is a PipeOp called imputemedian
# --- define with new -------------------------------------------------
ageImputeOp <- PipeOpImputeMedian$new( id = "impute_age" )
ageImputeOp$param_set$values$affect_columns = selector_name("age")
# --- or with the sugar function --------------------------------------
ageImputeOp <- pipeOp("imputemedian",
id = "impute_age",
affect_columns = selector_name("age"))The default action for most PipeOps is to apply the same action to every predictor. In this case each predictor would be median imputed. I only want to input the age so I set affect_columns.
From now on I will use the sugar functions with my own renaming.
I’ll run the two steps; zero to missing then impute missing
# --- capture Task from step 1 ----------------------------
partTask <- ageMutateOp$train( list(myTask))[[1]]
# --- impute on the saved Task ----------------------------
ageImputeOp$train( list(partTask))[[1]]$data() %>%
{ summary(.$age)}## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 3.00 10.00 12.00 10.93 12.00 42.00When the PipeOp are linked together in a pipeline, they can be run consecutively without the need to store the intermediate tasks.
All seems well and we can see from the summary that the median age that was used for imputation was 12. This value is saved in the PipeOps state. The state contains a lot of information that I don’t need. The important bit is the state’s model.
# --- extract the median ----------------------------------
ageImputeOp$state$model## $age
## [1] 12In this case the fitted model is just the median, which is 12.
Mass Production
The predictors min_time, max_time, avg_time, min_players and max_players also have zeros that need replacing with missing values.
# --- PipeOp to replace zeros by missing ---------------------------------------------
zeroMutationOp <- pipeOp( "mutate",
id = "zero_to_missing",
mutation = list(
age = ~ ifelse(age == 0 , NA, age),
min_time = ~ifelse( min_time == 0, NA, min_time),
max_time = ~ifelse( max_time == 0, NA, max_time),
avg_time = ~ifelse( avg_time == 0, NA, avg_time),
min_players = ~ifelse( min_players == 0, NA, min_players),
max_players = ~ifelse( max_players == 0, NA, max_players) )) Median imputation of each of these predictors
# --- median imputation -----------------------------------------------
imputeMedianOp <- pipeOp( "imputemedian",
id = "median_imputation",
affect_columns = selector_name(
c("age", "min_time", "max_time",
"avg_time", "min_players", "max_players")))Truncation
In my original analysis I decided to truncate several of the variables, for example games released before 1970 were grouped together as being from 1970. Truncations just requires more mutations, which I present without comment.
# --- create the truncation PipeOp ------------------------
truncationOp <- pipeOp("mutate",
id = "truncate",
mutation = list(
age = ~ pmin( age, 18),
max_players = ~ pmin(max_players, 25),
max_time = ~ pmin(max_time, 1000),
avg_time = ~ pmin(avg_time, (min_time+max_time)/2),
year = ~ pmax(year, 1970) ))Of course I could have combined the two mutate PipeOps into one with a longer list of mutations.
Log tranformation
I want to transform several of the predictors, I could do this using mutate but there is another way. The PipeOp colapply will apply a single function to any selection of columns.
# --- function to apply to a set of predictors ----------------------
logPredictorsOp <- pipeOp("colapply",
id = "log10_transform",
applicator = log10,
affect_columns = selector_name(
c("age", "min_time", "max_time",
"avg_time", "min_players", "max_players",
"owned", "num_votes")))Target Transformation
I also want to transform the response (target) but this presents an extra problem as mlr3 will need to be able to invert the transformation when it makes predictions. As a result, there will be two outputs from the PipeOp, the transformation and its inverse. When we fit the model we need the transformation and when making predictions we need the inverse. Setting this up manually is quite tedious so mlr3 provides a helper function ppl(), that does the work for you.
To use the short cut you have to be able to specify the learner that you plan to use. I will use a simple linear model fitted by R’s lm function.
yTransform <- function(...) ppl(...)
#--- define the learner --------------------------------
regModel <- setModel("regr.lm")
# --- use ppl to define the transformation --------------
logResponseOp <- yTransform("targettrafo",
graph = regModel,
targetmutate.trafo = function(x) log10(x - 5.5),
targetmutate.inverter = function(x) list(
response = 5.5 + 10 ^ x$response) )
# --- inspect the resulting pipeline --------------------
plot(logResponseOp)
Later I will combine this with the other PipeOps. If you want to understand what ppl() does, then there is an example in the mlr3gallery at https://mlr3gallery.mlr-org.com/posts/2020-06-15-target-transformations-via-pipelines/
Extracting Key Phases
The string variable mechanic contains phases that describe the game mechanics. They are separated by commas.
trainRawDF %>%
select( mechanic)## # A tibble: 3,499 x 1
## mechanic
## <chr>
## 1 Hand Management
## 2 Point to Point Movement, Route/Network Building
## 3 Betting/Wagering, Dice Rolling, Roll / Spin and Move
## 4 Secret Unit Deployment, Simultaneous Action Selection
## 5 Action Point Allowance System, Dice Rolling, Modular Board, Partnerships, Va~
## 6 Hand Management, Take That
## 7 Action Point Allowance System, Memory
## 8 Dice Rolling, Hex-and-Counter
## 9 Co-operative Play, Dice Rolling, Simulation
## 10 Dice Rolling, Hand Management
## # ... with 3,489 more rowsmlr3 has a PipeOp called textvectorizer that can extract key words from free text. It is very powerful and is built using the quanteda package. What we need here is rather different. We have fixed responses rather than free text and we want to note when the phases are present.
My analysis of Episode 11 of Sliced uses quanteda, but here I make a list of all of the possible phrases using good old dplyr
# --- Extract all possible mechanisms --------------------------
trainRawDF %>%
select( mechanic) %>%
separate(mechanic, sep=",",
into=paste("x", 1:10, sep=""),
remove=TRUE, extra="drop", fill="right" ) %>%
pivot_longer(everything(), values_to="terms", names_to="source" ) %>%
filter( !is.na(terms) ) %>%
mutate( terms = str_trim(terms)) %>%
filter( terms != "" ) %>%
group_by( terms) %>%
summarise( n = n() , .groups="drop") %>%
arrange( desc(n)) %>%
print() %>%
pull(terms) -> keyPhrases## # A tibble: 52 x 2
## terms n
## <chr> <int>
## 1 Dice Rolling 990
## 2 Hand Management 963
## 3 Variable Player Powers 644
## 4 Set Collection 511
## 5 Area Control / Area Influence 446
## 6 Card Drafting 415
## 7 Modular Board 401
## 8 Tile Placement 391
## 9 Hex-and-Counter 317
## 10 Action Point Allowance System 287
## # ... with 42 more rowsThere are 52 phrases in the dataset of which Dice Rolling is the most common.
I’ll make a tibble with 52 indicator (0/1) columns that encode whether each phase applies to that game. The code uses a map() function from purrr.
# --- named list of the phrases ------------------------------
phrases <- as.list(keyPhrases)
names(phrases) <- paste("M", 1:52, sep="")
# --- create indicators --------------------------------------
map_df(phrases, ~ as.numeric(str_detect(trainRawDF$mechanic, .x)) ) %>%
print() -> mecDF## # A tibble: 3,499 x 52
## M1 M2 M3 M4 M5 M6 M7 M8 M9 M10 M11 M12 M13
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0 1 0 0 0 0 0 0 0 0 0 0 0
## 2 0 0 0 0 0 0 0 0 0 0 0 0 0
## 3 1 0 0 0 0 0 0 0 0 0 0 0 0
## 4 0 0 0 0 0 0 0 0 0 0 0 1 0
## 5 1 0 1 0 0 0 1 0 0 1 0 0 0
## 6 0 1 0 0 0 0 0 0 0 0 0 0 0
## 7 0 0 0 0 0 0 0 0 0 1 0 0 0
## 8 1 0 0 0 0 0 0 0 1 0 0 0 0
## 9 1 0 0 0 0 0 0 0 0 0 1 0 0
## 10 1 1 0 0 0 0 0 0 0 0 0 0 0
## # ... with 3,489 more rows, and 39 more variables: M14 <dbl>, M15 <dbl>,
## # M16 <dbl>, M17 <dbl>, M18 <dbl>, M19 <dbl>, M20 <dbl>, M21 <dbl>,
## # M22 <dbl>, M23 <dbl>, M24 <dbl>, M25 <dbl>, M26 <dbl>, M27 <dbl>,
## # M28 <dbl>, M29 <dbl>, M30 <dbl>, M31 <dbl>, M32 <dbl>, M33 <dbl>,
## # M34 <dbl>, M35 <dbl>, M36 <dbl>, M37 <dbl>, M38 <dbl>, M39 <dbl>,
## # M40 <dbl>, M41 <dbl>, M42 <dbl>, M43 <dbl>, M44 <dbl>, M45 <dbl>,
## # M46 <dbl>, M47 <dbl>, M48 <dbl>, M49 <dbl>, M50 <dbl>, M51 <dbl>, M52 <dbl>I bind these indicators with trainRawDF in a re-definition of the task.
myTask$cbind(mecDF)The phrase extraction will not cause a problem of data leakage in a resampling design, but it could cause a problem if we were to randomly sample a set of games in which one of the rarer phrases was completely absent. This would create a predictor in which every value was zero. The PipeOp removeconstants will remove predictors that show no variation and would avoid this potential problem.
# --- PipeOp to remove constant predictors --------------------------
noConstantsOp <- pipeOp("removeconstants")I did not bother to give this PipeOp an identifier as there will only ever be one removeconstants PipeOp.
Dropping Predictors
Sometimes it is necessary to drop some of the potential predictors, in this example, before I fit the model, I want to drop the game identifier and all of the string variables. In doing this, those variables are removed from the list of potential predictors, they are not dropped from the data. The PipeOp select does the job.
First, I list all current features
# -- what features are available -------------------------------
myTask$feature_types## id type
## 1: M1 numeric
## 2: M10 numeric
## 3: M11 numeric
## 4: M12 numeric
## 5: M13 numeric
## 6: M14 numeric
## 7: M15 numeric
## 8: M16 numeric
## 9: M17 numeric
## 10: M18 numeric
## 11: M19 numeric
## 12: M2 numeric
## 13: M20 numeric
## 14: M21 numeric
## 15: M22 numeric
## 16: M23 numeric
## 17: M24 numeric
## 18: M25 numeric
## 19: M26 numeric
## 20: M27 numeric
## 21: M28 numeric
## 22: M29 numeric
## 23: M3 numeric
## 24: M30 numeric
## 25: M31 numeric
## 26: M32 numeric
## 27: M33 numeric
## 28: M34 numeric
## 29: M35 numeric
## 30: M36 numeric
## 31: M37 numeric
## 32: M38 numeric
## 33: M39 numeric
## 34: M4 numeric
## 35: M40 numeric
## 36: M41 numeric
## 37: M42 numeric
## 38: M43 numeric
## 39: M44 numeric
## 40: M45 numeric
## 41: M46 numeric
## 42: M47 numeric
## 43: M48 numeric
## 44: M49 numeric
## 45: M5 numeric
## 46: M50 numeric
## 47: M51 numeric
## 48: M52 numeric
## 49: M6 numeric
## 50: M7 numeric
## 51: M8 numeric
## 52: M9 numeric
## 53: age numeric
## 54: avg_time numeric
## 55: category1 character
## 56: category10 character
## 57: category11 character
## 58: category12 character
## 59: category2 character
## 60: category3 character
## 61: category4 character
## 62: category5 character
## 63: category6 character
## 64: category7 character
## 65: category8 character
## 66: category9 character
## 67: designer character
## 68: game_id numeric
## 69: max_players numeric
## 70: max_time numeric
## 71: mechanic character
## 72: min_players numeric
## 73: min_time numeric
## 74: names character
## 75: num_votes numeric
## 76: owned numeric
## 77: year numeric
## id typeNext I drop the character variables
# --- drop unwanted features -----------------------------------
dropFeaturesOp <- pipeOp("select",
id = "drop_features",
selector = selector_invert(
selector_union(selector_type("character"),
selector_name("game_id") )))What is left
dropFeaturesOp$train(list( myTask))[[1]]$feature_names## [1] "age" "avg_time" "max_players" "max_time" "min_players"
## [6] "min_time" "num_votes" "owned" "year" "M1"
## [11] "M2" "M3" "M4" "M5" "M6"
## [16] "M7" "M8" "M9" "M10" "M11"
## [21] "M12" "M13" "M14" "M15" "M16"
## [26] "M17" "M18" "M19" "M20" "M21"
## [31] "M22" "M23" "M24" "M25" "M26"
## [36] "M27" "M28" "M29" "M30" "M31"
## [41] "M32" "M33" "M34" "M35" "M36"
## [46] "M37" "M38" "M39" "M40" "M41"
## [51] "M42" "M43" "M44" "M45" "M46"
## [56] "M47" "M48" "M49" "M50" "M51"
## [61] "M52"Filtering
After dropping the strings and identifiers there will be 61 possible predictors. For some models it is necessary to feature select prior to model fitting, in mlr3 this is done with a filter. A filter is not itself a PipeOp but once created it can be inserted into a PipeOp.
There are many filters provided by the package mlr3filters as can be seen from https://mlr3book.mlr-org.com/appendix.html or by printing contents of the dictionary that stores their names.
mlr_filters## <DictionaryFilter> with 19 stored values
## Keys: anova, auc, carscore, cmim, correlation, disr, find_correlation,
## importance, information_gain, jmi, jmim, kruskal_test, mim, mrmr,
## njmim, performance, permutation, relief, varianceThe filter correlation is one of the simplest, it chooses the predictors with the largest absolute correlation to the response. Here is such a filter.
# --- Create a correlation filter ----------------------------------
corFilter <- setFilter("correlation")
# --- drop strings and the id --------------------------------------
smallTask <- dropFeaturesOp$train(list(myTask))[[1]]
# --- apply correlation filter to the remaining predictors ---------
corFilter$calculate(smallTask)
# --- show the absolute correlations -------------------------------
as.data.table(corFilter)## feature score
## 1: num_votes 0.648535629
## 2: owned 0.638831344
## 3: M3 0.185533043
## 4: age 0.161868048
## 5: M6 0.155695698
## 6: M9 0.153654275
## 7: M15 0.140097318
## 8: M2 0.135833960
## 9: M5 0.133068536
## 10: M33 0.111895188
## 11: M27 0.110192636
## 12: M16 0.108594547
## 13: M18 0.099994897
## 14: M10 0.094210104
## 15: M14 0.094048040
## 16: M42 0.078857711
## 17: M11 0.078069407
## 18: M7 0.076150946
## 19: M4 0.074788323
## 20: M29 0.074745328
## 21: M13 0.069072392
## 22: M19 0.065834500
## 23: M30 0.057519123
## 24: M21 0.057259794
## 25: M20 0.056175144
## 26: M41 0.053039720
## 27: M17 0.052891144
## 28: M12 0.051783371
## 29: M40 0.049851052
## 30: M22 0.049661995
## 31: M32 0.046432962
## 32: M47 0.039698666
## 33: M37 0.039392064
## 34: M8 0.037942921
## 35: M34 0.034718427
## 36: M38 0.033000262
## 37: M44 0.032968116
## 38: min_players 0.032768111
## 39: M26 0.031865539
## 40: M48 0.028688666
## 41: M1 0.028305055
## 42: M43 0.025560229
## 43: M24 0.025237677
## 44: min_time 0.023188890
## 45: M52 0.019815224
## 46: M39 0.019160129
## 47: M46 0.018992873
## 48: M49 0.018457101
## 49: M25 0.016859180
## 50: max_players 0.015327948
## 51: avg_time 0.014488493
## 52: M50 0.014396461
## 53: max_time 0.014000777
## 54: M51 0.013917298
## 55: M36 0.013069618
## 56: M45 0.012609392
## 57: M28 0.010686335
## 58: M35 0.009745224
## 59: M23 0.007110701
## 60: year 0.005827105
## 61: M31 0.004009631
## feature scoreThe filter calculates the statistic that is to be used in filtering but it does not itself make a selection. To do that we need to place the filter in a PipeOp.
I create a PipeOp that uses this filter to pick the 10 ten correlations
# --- create filtering PipeOp ---------------------------------
corFilterOp <- pipeOp("filter",
id = "correlation_filter",
filter = corFilter,
filter.nfeat = 10)
# --- apply the PipeOp to the remaining features --------------
corFilterOp$train(list(smallTask))[[1]]$feature_names## [1] "age" "num_votes" "owned" "M2" "M3" "M5"
## [7] "M6" "M9" "M15" "M33"Of course, the selected features might change after the predictors have been log transformed.
Making a Pipeline
PipeOps are combined using the %>>% operator.
# --- Pipeline for pre-processing -----------------
# --- zero to missing -----------
zeroMutationOp %>>%
# --- median imputation ---------
imputeMedianOp %>>%
# --- feature truncation --------
truncationOp %>>%
# --- drop unwanted features ----
dropFeaturesOp %>>%
# --- log transform -------------
logPredictorsOp %>>%
# --- drop constant features ----
noConstantsOp %>>%
# --- filter by correlation -----
corFilterOp %>>%
# --- transform response --------
logResponseOp -> myPipeline
plot(myPipeline)
The pipeline can be converted in a learner so that the entire process can be trained, resampled or tuned
# --- convert pipeline to a learner ---------------------
myAnalysis <- as_learner(myPipeline)
# --- train: pre-process & fit model --------------------
myAnalysis$train(myTask)I could look at the fit but I would get the fit (results) for every step in the pipeline and not just the regression model.
# --- model results for every step in the analysis ------
myAnalysis$modelFor the regression model fit I need
# --- not a good idea: very long -----------------------
myAnalysis$model$regr.lm$model##
## Call:
## stats::lm(formula = task$formula(), data = task$data())
##
## Coefficients:
## (Intercept) age num_votes owned M2 M3
## -2.30216 0.39943 0.47803 0.04444 -0.01367 0.03175
## M5 M6 M9 M15 M33
## 0.02474 0.02566 0.05324 0.06612 0.04508This is just the returned structure of lm().
I could even use everyone’s favourite package, broom
# --- table of model coefficients ----------------------
broom::tidy(myAnalysis$model$regr.lm$model)## # A tibble: 11 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) -2.30 0.0337 -68.3 0.
## 2 age 0.399 0.0283 14.1 5.87e- 44
## 3 num_votes 0.478 0.0189 25.3 1.17e-129
## 4 owned 0.0444 0.0208 2.13 3.30e- 2
## 5 M2 -0.0137 0.00632 -2.16 3.07e- 2
## 6 M3 0.0317 0.00736 4.32 1.64e- 5
## 7 M5 0.0247 0.00831 2.98 2.94e- 3
## 8 M6 0.0257 0.00864 2.97 2.98e- 3
## 9 M9 0.0532 0.0109 4.90 1.01e- 6
## 10 M15 0.0661 0.0109 6.07 1.43e- 9
## 11 M33 0.0451 0.0174 2.59 9.53e- 3At present the correlation filter looks at the correlations before the target is transformed.
# --- filter after transforming y --------------
logResponseOp <- yTransform("targettrafo",
graph = corFilterOp %>>% regModel,
targetmutate.trafo = function(x) log10(x - 5.5),
targetmutate.inverter = function(x) list(
response = 5.5 + 10 ^ x$response) )
# --- redefine the pipeline ----------------------
# --- zero to missing -----------
zeroMutationOp %>>%
# --- median imputation ---------
imputeMedianOp %>>%
# --- feature truncation --------
truncationOp %>>%
# --- drop unwanted features ----
dropFeaturesOp %>>%
# --- log transform -------------
logPredictorsOp %>>%
# --- drop constant features ----
noConstantsOp %>>%
# --- transform response --------
# --- then filter, then fit -----
logResponseOp -> myNewPipeline
plot(myNewPipeline)
# --- make a new analysis ------------------------------
myNewAnalysis <- as_learner(myNewPipeline)
# --- run the analysis ---------------------------------
myNewAnalysis$train(myTask)
# --- table of coefficients ----------------------------
broom::tidy(myNewAnalysis$model$regr.lm$model)## # A tibble: 11 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) -2.30 0.0341 -67.4 0.
## 2 age 0.398 0.0284 14.0 3.08e- 43
## 3 num_votes 0.477 0.0189 25.2 3.74e-129
## 4 owned 0.0452 0.0208 2.17 3.01e- 2
## 5 M2 -0.0155 0.00636 -2.45 1.45e- 2
## 6 M3 0.0323 0.00735 4.39 1.15e- 5
## 7 M5 0.0256 0.00830 3.08 2.10e- 3
## 8 M6 0.0251 0.00865 2.90 3.73e- 3
## 9 M9 0.0516 0.0109 4.73 2.32e- 6
## 10 M15 0.0674 0.0109 6.20 6.34e- 10
## 11 M27 -0.0279 0.0154 -1.81 7.03e- 2Notice that predictor M27 has been selected where previously we had M33.
Even though the model has been fitted to the transformed response, the predictions are made on the original scale because the target transformation knows how to invert y.
# --- predictions for the new analysis ---------------------
myPredictions <- myNewAnalysis$predict(task = myTask)
# --- predictions are on the original scale ----------------
myPredictions$print()## <PredictionRegr> for 3499 observations:
## row_ids truth response
## 1 5.70135 5.819208
## 2 5.92648 5.840950
## 3 6.37107 6.916004
## ---
## 3497 5.72251 5.861026
## 3498 5.66587 5.675672
## 3499 6.04041 6.377437broom::glance(myNewAnalysis$model$regr.lm$model)## # A tibble: 1 x 12
## r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0.763 0.762 0.160 1121. 0 10 1443. -2861. -2787.
## # ... with 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>The R2 value is a measure of model performance but it ignores the uncertainty over the pre-processing, in particular the filtering. This R2 value would apply if these 10 features were selected without reference to the training data. Perhaps we should cross-validate the entire analysis.
# --- seed for reproducibility ----------------------------
set.seed(9372)
# --- define the sampler; here 10-fold cross-validation ---
myCV <- setSampler("cv")
# --- prepare the folds from myTask -----------------------
myCV$instantiate(task = myTask)
# --- run the cross-validation ----------------------------
rsFit <- resample( task = myTask,
learner = myNewAnalysis,
resampling = myCV)## INFO [10:58:25.044] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:58:26.224] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:58:27.383] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:58:28.715] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:58:29.857] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:58:30.992] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:58:32.148] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:58:33.282] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:58:34.433] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:58:35.595] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)# --- choose a performance measure ------------------------
myMeasure <- setMeasure("regr.rsq")
# --- look at performance across the 10 folds -------------
rsFit$score(myMeasure)## task task_id learner
## 1: <TaskRegr[44]> Boardgame rating <GraphLearner[35]>
## 2: <TaskRegr[44]> Boardgame rating <GraphLearner[35]>
## 3: <TaskRegr[44]> Boardgame rating <GraphLearner[35]>
## 4: <TaskRegr[44]> Boardgame rating <GraphLearner[35]>
## 5: <TaskRegr[44]> Boardgame rating <GraphLearner[35]>
## 6: <TaskRegr[44]> Boardgame rating <GraphLearner[35]>
## 7: <TaskRegr[44]> Boardgame rating <GraphLearner[35]>
## 8: <TaskRegr[44]> Boardgame rating <GraphLearner[35]>
## 9: <TaskRegr[44]> Boardgame rating <GraphLearner[35]>
## 10: <TaskRegr[44]> Boardgame rating <GraphLearner[35]>
## learner_id
## 1: zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert
## 2: zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert
## 3: zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert
## 4: zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert
## 5: zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert
## 6: zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert
## 7: zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert
## 8: zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert
## 9: zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert
## 10: zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert
## resampling resampling_id iteration prediction regr.rsq
## 1: <ResamplingCV[19]> cv 1 <PredictionRegr[18]> 0.7451363
## 2: <ResamplingCV[19]> cv 2 <PredictionRegr[18]> 0.6587752
## 3: <ResamplingCV[19]> cv 3 <PredictionRegr[18]> 0.7677487
## 4: <ResamplingCV[19]> cv 4 <PredictionRegr[18]> 0.5105902
## 5: <ResamplingCV[19]> cv 5 <PredictionRegr[18]> 0.6834928
## 6: <ResamplingCV[19]> cv 6 <PredictionRegr[18]> 0.6217273
## 7: <ResamplingCV[19]> cv 7 <PredictionRegr[18]> 0.6448513
## 8: <ResamplingCV[19]> cv 8 <PredictionRegr[18]> 0.7608137
## 9: <ResamplingCV[19]> cv 9 <PredictionRegr[18]> 0.5328952
## 10: <ResamplingCV[19]> cv 10 <PredictionRegr[18]> 0.6024001# --- average performance ---------------------------------
rsFit$aggregate(myMeasure)## regr.rsq
## 0.6528431As expected, the cross-validated value of R2 for the entire pipeline is quite a bit lower than the output from lm() alone suggested.
Why just use the top 10 features? perhaps more would be better. I will tune the number of predictors taken from the filter.
# --- use the future package to create the sessions ---------------------
future::plan("multisession")
# --- set the hyperparameters to be tuned -------------------------------
myNewAnalysis$param_set$values$correlation_filter.filter.nfeat = to_tune(10, 50)
# --- run a grid of 10 values ---------------------------------------
set.seed(9830)
myTuner <- tune(
method = "grid_search",
task = myTask,
learner = myNewAnalysis,
resampling = myCV,
measure = myMeasure,
term_evals = 10,
batch_size = 5
)## INFO [10:58:39.733] [bbotk] Starting to optimize 1 parameter(s) with '<OptimizerGridSearch>' and '<TerminatorEvals> [n_evals=10]'
## INFO [10:58:39.736] [bbotk] Evaluating 5 configuration(s)
## INFO [10:58:40.164] [mlr3] Running benchmark with 50 resampling iterations
## INFO [10:58:40.652] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:58:42.405] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:58:44.591] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:58:46.994] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:58:49.714] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:58:52.132] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:58:54.626] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:58:41.213] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)
## INFO [10:58:43.213] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:58:45.432] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:58:47.827] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:58:50.566] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:58:52.974] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:58:41.799] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:58:44.035] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)
## INFO [10:58:46.417] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:58:48.982] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:58:51.468] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:58:54.077] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)
## INFO [10:58:42.432] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:58:44.764] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:58:47.213] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:58:49.857] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:58:52.242] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:58:54.795] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:58:43.229] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:58:45.733] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:58:48.238] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:58:50.797] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:58:53.286] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:58:55.830] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:58:44.055] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:58:46.737] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:58:49.372] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:58:51.761] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:58:54.299] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)
## INFO [10:58:56.476] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:58:44.916] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:58:47.563] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:58:50.275] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:58:52.631] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:58:55.229] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:58:57.253] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:58:45.813] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:58:48.559] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:58:51.140] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)
## INFO [10:58:53.603] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:58:55.973] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:58:57.693] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:58:58.913] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:59:00.156] [mlr3] Finished benchmark
## INFO [10:59:00.616] [bbotk] Result of batch 1:
## INFO [10:59:00.618] [bbotk] correlation_filter.filter.nfeat regr.rsq uhash
## INFO [10:59:00.618] [bbotk] 14 0.6788379 3cae3f3c-912c-46f4-9ad6-1f2b75f81294
## INFO [10:59:00.618] [bbotk] 23 0.6869976 13973f8c-41e6-46e7-8604-7a90c3bf8a9b
## INFO [10:59:00.618] [bbotk] 28 0.6810663 28a70f11-e72e-469a-879e-816f99e95541
## INFO [10:59:00.618] [bbotk] 32 0.6816229 bccfd5bd-d360-468a-a425-17d729ac2e35
## INFO [10:59:00.618] [bbotk] 37 0.6860195 626f0409-9109-445f-99f9-ccb826ee0ad8
## INFO [10:59:00.619] [bbotk] Evaluating 5 configuration(s)
## INFO [10:59:00.886] [mlr3] Running benchmark with 50 resampling iterations
## INFO [10:59:00.970] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:59:03.261] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:59:05.857] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:59:08.278] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:59:10.639] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:59:13.165] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)
## INFO [10:59:15.680] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:59:01.035] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:59:03.490] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:59:05.916] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:59:08.286] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:59:10.697] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:59:13.267] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)
## INFO [10:59:01.086] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:59:03.484] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:59:05.876] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:59:08.301] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:59:10.814] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:59:13.335] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:59:01.148] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)
## INFO [10:59:03.543] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:59:05.915] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)
## INFO [10:59:08.448] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:59:10.916] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:59:13.355] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:59:01.211] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:59:03.719] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:59:06.096] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:59:08.556] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:59:11.048] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:59:13.537] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:59:01.346] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:59:03.767] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:59:06.293] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:59:08.705] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:59:11.365] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:59:13.710] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:59:01.435] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 4/10)
## INFO [10:59:03.905] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:59:06.313] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 5/10)
## INFO [10:59:08.893] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 10/10)
## INFO [10:59:11.492] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 3/10)
## INFO [10:59:13.842] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 2/10)
## INFO [10:59:01.844] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:59:04.378] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 7/10)
## INFO [10:59:06.970] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:59:09.346] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 8/10)
## INFO [10:59:11.897] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 9/10)
## INFO [10:59:14.330] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 6/10)
## INFO [10:59:16.264] [mlr3] Applying learner 'zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert' on task 'Boardgame rating' (iter 1/10)
## INFO [10:59:17.521] [mlr3] Finished benchmark
## INFO [10:59:18.002] [bbotk] Result of batch 2:
## INFO [10:59:18.003] [bbotk] correlation_filter.filter.nfeat regr.rsq uhash
## INFO [10:59:18.003] [bbotk] 10 0.6528431 ead8cc73-55c3-4a96-bf9a-9b6f4da19f82
## INFO [10:59:18.003] [bbotk] 19 0.6904128 57eb7d4a-013c-4bd7-b4bc-df6a30088e16
## INFO [10:59:18.003] [bbotk] 41 0.6851661 8528b177-6d0f-4d22-aff6-026b50437dca
## INFO [10:59:18.003] [bbotk] 46 0.6861537 b21b1a5d-3eb5-488a-b720-f0422ccc3e1c
## INFO [10:59:18.003] [bbotk] 50 0.6850456 a4085cfb-9d2b-45ee-8bbe-f85e1b47a0df
## INFO [10:59:18.012] [bbotk] Finished optimizing after 10 evaluation(s)
## INFO [10:59:18.012] [bbotk] Result:
## INFO [10:59:18.013] [bbotk] correlation_filter.filter.nfeat learner_param_vals x_domain regr.rsq
## INFO [10:59:18.013] [bbotk] 19 <list[15]> <list[1]> 0.6904128myTuner## <TuningInstanceSingleCrit>
## * State: Optimized
## * Objective: <ObjectiveTuning:zero_to_missing.median_imputation.truncate.drop_features.log10_transform.removeconstants.targetmutate.correlation_filter.regr.lm.targetinvert_on_Boardgame
## rating>
## * Search Space:
## <ParamSet>
## id class lower upper nlevels default
## 1: correlation_filter.filter.nfeat ParamInt 10 50 41 <NoDefault[3]>
## value
## 1:
## * Terminator: <TerminatorEvals>
## * Terminated: TRUE
## * Result:
## correlation_filter.filter.nfeat learner_param_vals x_domain regr.rsq
## 1: 19 <list[15]> <list[1]> 0.6904128
## * Archive:
## <ArchiveTuning>
## correlation_filter.filter.nfeat regr.rsq timestamp batch_nr
## 1: 14 0.68 2021-11-15 10:59:00 1
## 2: 23 0.69 2021-11-15 10:59:00 1
## 3: 28 0.68 2021-11-15 10:59:00 1
## 4: 32 0.68 2021-11-15 10:59:00 1
## 5: 37 0.69 2021-11-15 10:59:00 1
## 6: 10 0.65 2021-11-15 10:59:18 2
## 7: 19 0.69 2021-11-15 10:59:18 2
## 8: 41 0.69 2021-11-15 10:59:18 2
## 9: 46 0.69 2021-11-15 10:59:18 2
## 10: 50 0.69 2021-11-15 10:59:18 2The tuning says that 19 features is best, but I do not believe it. The R2 values from 10-fold cross-validation are themselves subject to a sampling error that is greater than any differences that we see.
# --- plot cv R2 by number of features ------------------------------
myTuner$archive %>%
as.data.table() %>%
as_tibble() %>%
ggplot( aes(x=correlation_filter.filter.nfeat, y=regr.rsq)) +
geom_point() +
geom_line()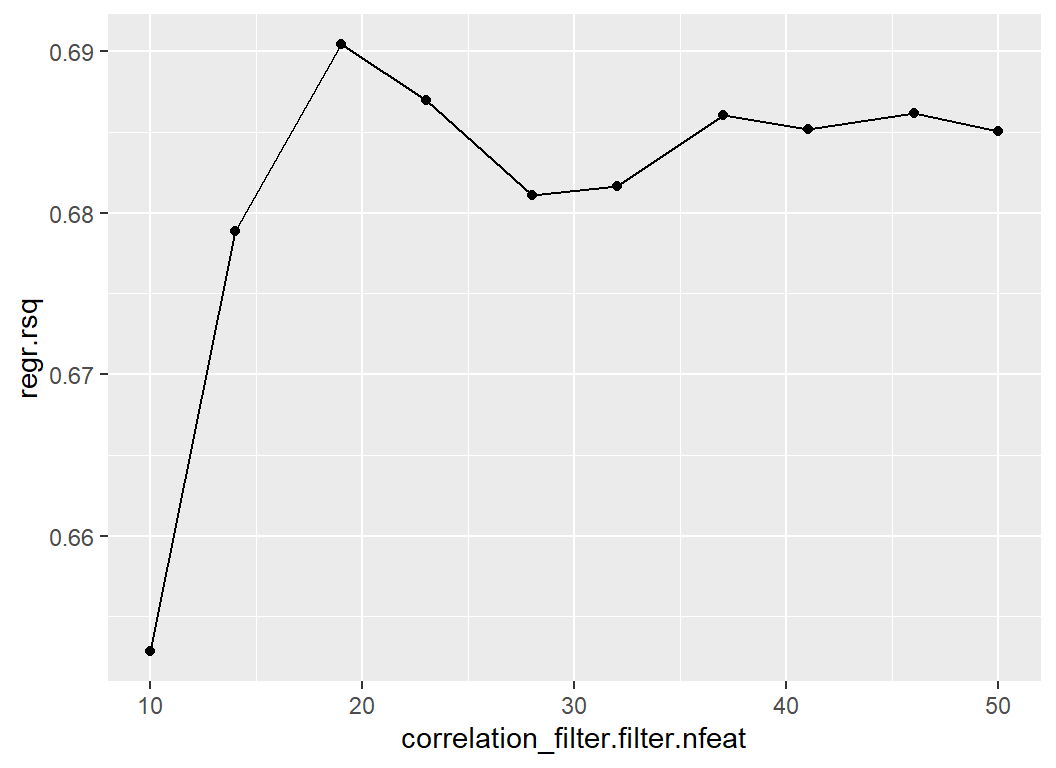
I am sure that you will have spotted that correlation is a terrible filter, many of the other filters offered by mlr3 would do much better. I should also use splines for age, num_votes and owners.